 Facebook
Facebook Google
Google GitHub
GitHub Linkedin
LinkedinCan Generative AI and Large Language Models Help Catch More Krill?
This article reviews the challenges and opportunities when incorporating generative AI and Large Language Models in industrial applications. It also examines how a Norwegian fishing and biotech company improved operational productivity and efficiency using generative AI.
Recent software developments have unlocked a rate of industry progress that rivals the pace of advancement during the Industrial Revolution. Generative AI is one such tool that is coming into vogue. When used correctly in industrial settings, the technology enables easier collaboration, task automation, and waste reduction. But Generative AI is only as strong as its data foundation.
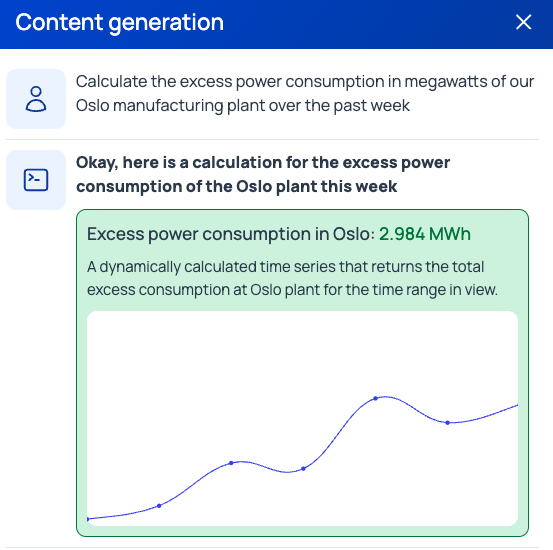
Figure 1. Example of using generative AI for industrial data insights. Image used courtesy of Cognite
Asset-heavy industries planning to incorporate Generative AI into their digital transformation strategies must address three common roadblocks during adoption. An effective Generative AI implementation will include fail-safes for hallucinations and data leakage, as well as access control to ensure privacy and security. Let's examine these three roadblocks in more detail.
Hallucinations
Artificial Intelligence (AI) and the availability of Large Language Models (LLMs) are democratizing data in industrial environments. While generally positive, data access only solves some of the problems. Data must be high quality to produce accurate results. When almost accurate or probabilistic data is used as a foundation for Generative AI, there is a higher likelihood of receiving inaccurate responses called hallucinations.
Hallucinations are a frequent issue for LLMs and Generative AI platforms like ChatGPT that are trained on public internet data. While these platforms add new, valuable capabilities to software applications, they tend to generate false information when the query depends on private data that is not available on the public internet. These generative results are plausible by design, but not necessarily based on real facts and often lack necessary context. Hallucinations seem convincing, and that makes them detrimental to the functionality of Generative AI in industrial applications. To reduce the likelihood of hallucinations, make sure any database for generative AI consists of current, accurate data.
Data Leakage
Data leakage is a prominent cybersecurity concern when data is distributed over different devices and networks. Proprietary enterprise data is often sensitive, including product designs, trade secrets, or customer information. Releasing data, even unknowingly, into the public domain is nothing short of corporate blasphemy. For this reason, unauthorized transmission of data from inside an organization to external parties must be addressed prior to Generative AI implementation.
Access Control to Create Privacy and Security
Access control is essential to avoid data leaks. Like any advanced technology, LLMs can be vulnerable to adversarial attacks. In an industrial setting, these concerns are magnified due to the often proprietary nature of industry data. Ensuring proper anonymization, safeguarding LLM infrastructure, securing data transfers, and implementing robust authentication mechanisms are vital steps to mitigate cybersecurity risks and protect sensitive information.
An Overarching Solution
Improving data quality for LLMs and Generative AI is an essential step in the implementation process. To do this, you first must understand your physical world and where the data that will feed into a system is coming from. Knowledge graphs use machine learning to present a holistic view of data. Constructed by combining different data sources, knowledge graphs map where information comes from and the relationships between each source. The graph processes data through normalization, scaling, and augmentation to ensure accurate and trustworthy generative responses. Creating an industrial knowledge graph is one way to ensure data integrity and end hallucinations.
To gather the necessary facts, AI solutions should include flexible data modeling and be queryable with a programming language (API). Solutions must use the large language model to translate the user query into a programmatic query. Luckily this translation is exactly what LLMs were built for.
RAG is All the Rage
An innovative architecture that unifies Generative AI with data modeling and Retrieval-Augmented Generation (RAG) capabilities is the most effective way to implement this new technology. RAG, which is a design pattern that provides industrial data directly to an LLM as specific content for formulating a response, lets users use off-the-shelf LLMs and control their behavior through conditioning on private contextualized data.
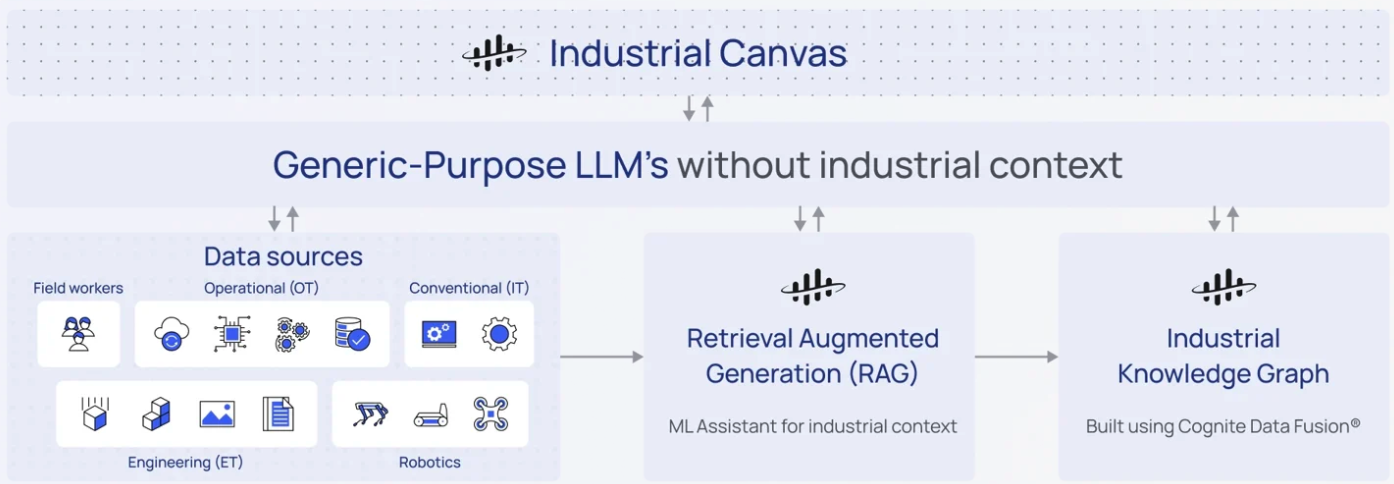
Figure 2. A method for incorporating retrieval augmented generation. Image used courtesy of Cognite (click to enlarge)
Using this setup eliminates hallucinations, mitigates data leakage, and enables effective access control. RAG creates a secure environment to keep industrial data proprietary within your corporate tenant—building trust with large enterprises and meeting stringent security and audit requirements.
This approach gives industry users the best of both worlds. The large language model translates human language to programmable language, removing a barrier to entry that would otherwise prevent many users from getting the most out of the technology. Every single user in the organization can use Generative AI because it only requires them to write what they want in human language. The flexible data model delivers results with no hallucinations or data leakage, full access control, a clear data lineage, and high data quality.
Case Study: Aker BioMarine
Aker BioMarine, the world’s leading krill harvester and supplier, uses this strategy to digitally transform its offshore and manufacturing operations. Before working with Cognite, its industrial DataOps partner, Aker BioMarine gathered their data manually, compiling one set of data per day with many parameters in an Excel spreadsheet. Once a month, engineering would do a rough calculation that gave the team a high-level understanding of whether their chemical process was up to the correct standard. If the standards were wrong, the data indicated that some of the machines or process steps were not run optimally; however, the exact reason and location were not easily found.

Figure 3. Antarctic krill. Image used courtesy of Adobe Stock
By utilizing Cognite Data Fusion and generative AI, Aker BioMarine’s engineers no longer have to spend time collecting or calculating their data and can instead use their time preventing and solving issues that occur. Aker BioMarine extracts data from their file systems and time series databases using Cognite's extractors, and assets are constructed programmatically either based on SME knowledge or based on recognition of assets from time series names or file names. This results in a classic asset hierarchy with linked files and time series.
Once assets with associated time series and technical documents are available in Cognite Data Fusion, queries can be made across data types. For example, users can ask the platform to show all time series for Houston's machinery of type SMB (simulated moving bed). Users can further specify to only be shown data where the value has exceeded norms in the last month. From there, the information is returned as either a visual graph, a text response, or a table of values, depending on what users asked Cognite Data Fusion to answer.
Cognite Data Fusion has liberated and contextualized data from different parts of Aker BioMarine’s operations, including krill exploration and manufacturing process, delivering more accessible live and historical data from multiple sources. Aker BioMarine’s data transformation has simplified complex data exploration, freed up valuable time for engineers to focus on problem-solving rather than gathering data, and offered operators and production managers real-time information to adjust production to avoid downtime.
The company’s Houston plant alone produced millions of data points for ingestion and contextualization. This process provided instant access to in-process and synthetic time series data analytics, giving engineers unique insight into root cause analysis and process efficiency to improve overall decision-making.
Aker BioMarine worked with Cognite to implement the technology. Aker BioMarine then scaled the solution to connect information from its three vessels in Antarctica to the Houston plant, further improving operational productivity and efficiency.

Figure 4. Krill fishing vessel. Image used courtesy of Aker BioMarine
Ultimately, Aker BioMarine’s digital transformation with Cognite saw a significant reduction in unit cost of operation in just two years, a consequential reduction in downtime from improved operations, and increased output with new machinery.
Generative AI is a game-changer in industry. Integrating data contextualization, industrial knowledge graphs, and RAG technology lays the groundwork for successful and transformative language (API) that can deliver quality results.
To learn more about making generative AI work for industry, download The Definitive Guide to Generative AI for Industry, a free resource authored by AI innovators at Cognite.








