 Facebook
Facebook Google
Google GitHub
GitHub Linkedin
LinkedinToyota Reveals Diffusion Policy Best Way to Teach Today’s Robots Tomorrow’s Tricks
New, generative AI-based approach set to revolutionize robotic programming.
Toyota Research Institute (TRI) announced a breakthrough approach to programming that it says can significantly improve and extend the dexterity and utility of industrial robots. According to TRI, by applying Diffusion Policy, and advanced generative artificial intelligence (AI), engineers are now better equipped to efficiently teach robots more human-like behaviors in a fraction of the time.
Another Level of Robot Learning Entirely
Instead of image generation conditioned on natural language, TRI and its collaborators within Professor Shuran Song’s group at Columbia University developed Diffusion Policy, which enables easy and rapid behavior teaching by learning from demonstration training. Diffusion Policy can generate robot actions conditioned on sensor observations of human movement and natural language.
Previous techniques to teach robots new tricks notes TRI, were “slow, inconsistent, inefficient, and often limited to narrowly defined tasks performed in highly constrained environments.” Before the application of Diffusion Policy-based programming, roboticists, they claim, were doomed to spend many long, and unnecessary hours writing sophisticated code and executing countless trial-and-error cycles to program robots to behave more like humans.
TRI and Dr. Song’s development work demonstrated the process enables new motions or behaviors to be deployed autonomously from dozens of demonstrations. According to TRI not only does this approach produce better robot learning performance, but it also delivers consistent, repeatable results at tremendous speed.

According to TRI, Diffusion Policy not only produces better robot learning performance, it also delivers consistent, repeatable results at tremendous speed. Image used courtesy of TRI
How Diffusion Policy Learning Works
Once a set of demonstrations has been collected, for a particular behavior, TRI explains, robots learn to perform a behavior autonomously. In the simple block-pushing example shown in Figure 1, the robot’s action space is in a 2D position, making it possible to easily visualize behavior being “diffused” by the learned policy. At each timestep, the policy starts with a random trajectory for the finger which is then diffused into a coherent plan which is executed by the robot. This process repeats multiple times a second.
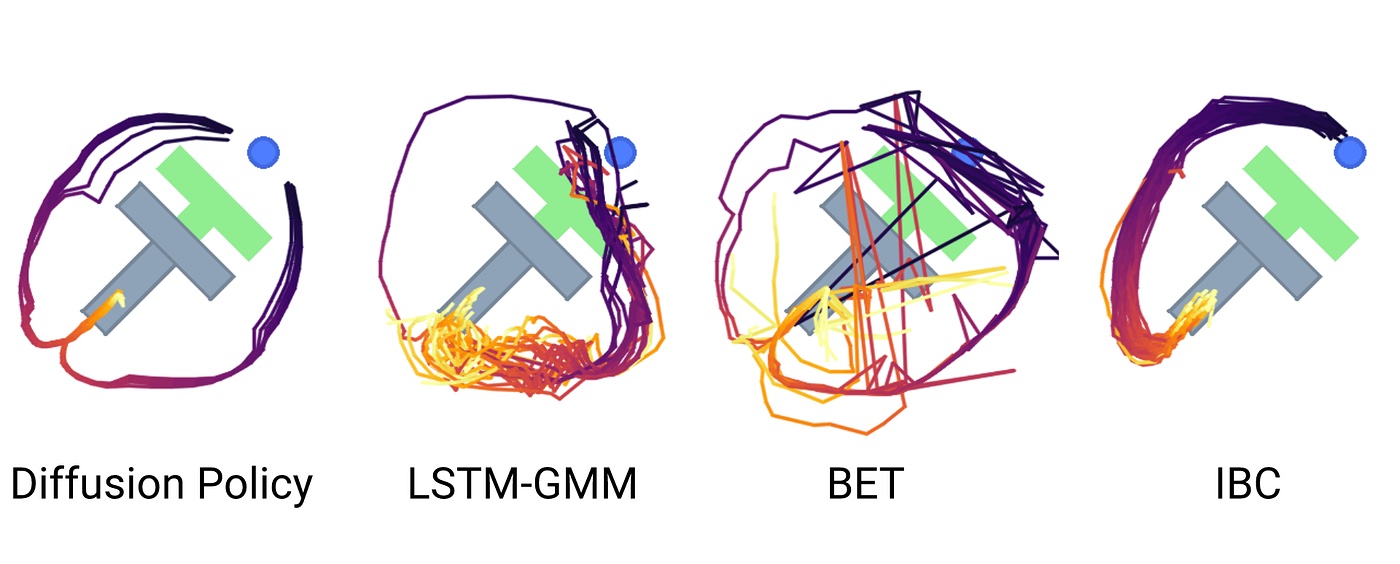
Figure 1. Sampled behavior on the Push-T domain, Diffusion Policy vs. prior approaches. Image used courtesy of TRI
TRI’s robot behavior model learns from haptic demonstrations from a teacher, combined with a language description of the goal. It then uses an AI-based Diffusion Policy to learn the demonstrated skill. This process allows a new behavior to be deployed autonomously from dozens of demonstrations.
According to the Toyota research team, researchers, employing four different robot manipulation benchmarks across 12 different tasks found Diffusion Policy consistently outperformed commercially applied robot learning methods “with an average improvement of 46.9%.”
Study results, noted by the paper’s authors, demonstrated how Diffusion Policy helps robots learn action-distribution score function gradients faster and iteratively optimizes gradient fields during inference via a series of stochastic Langevin dynamics steps.
Not only does this approach produce consistent, repeatable, and performant results, says Toyota, but it does so with tremendous speed. Applying Diffusion Policy to generate robot motion and routines provides three key benefits over prior methods:
- Supports multi-modal demonstrations allowing human demonstrators to teach behaviors naturally and not worry about disrupting robot learning.
- Suitability to high-dimensional action spaces which allows robots to plan forward in time and avoid erratic behavior.
- Stable and reliable for training robots at scale.
So Embarrassingly Simple Even a Robot Can Do It
Toyota’s marketing team explains Diffusion Policy is “embarrassingly simple to train,” noting new behaviors can be taught without the necessity of expensive real-world evaluations or taking the time to program in best-performing checkpoints and hyperparameters. Toyota researchers explain that any robot learning pipeline that requires extensive tuning or hyperparameter optimization is impractical because of this bottleneck in real-life evaluation. Because Diffusion Policy works out of the box so consistently, says TRI, it allows robot programmers and trainers to bypass it altogether.
Interestingly enough TRI says their achievements were realized without writing a single line of new code. According to the company, the only change was providing the robot with new data. TRI plans to build on this success, setting an ambitious target to teach hundreds of new skills to its robots by the end of 2023, reaching 1,000 by the end of 2024.
Toyota’s research demonstrates that robots can be taught more human-like routines and motions without the complexity or expense. These skills are not limited to just “‘pick and place” or simply pushing around objects to new locations. Through Diffusion Poilicy robots can interact with the world in varied and rich ways — which means that soon robots will be even better at supporting people with everyday situations and tasks.
“The tasks that I’m watching these robots perform are simply amazing – even one year ago, I would not have predicted that we were close to this level of diverse dexterity,” remarked Russ Tedrake, Vice President of Robotics Research at TRI. According to TRI Dr. Tedrake, is the Toyota Professor of Electrical Engineering and Computer Science, Aeronautics and Astronautics, and Mechanical Engineering at MIT. “What is so exciting about this new approach,” explains Dr. Tedrake, “is the rate and reliability with which we can add new skills. Because these skills work directly from camera images and tactile sensing, using only learned representations, they can perform well even on tasks that involve deformable objects, cloth, and liquids — all of which have traditionally been extremely difficult for robots.”








